Visual aggregates
Posted by ognjen in General, Scripts And How-Tos on October 30, 2018
There is a number of built-in aggregates in Informix which are there for what seams like forever, and it didn’t change throughout many version now. If you’re using SQL, you surely use aggregates – COUNT, SUM, AVG, to name just a few. And if you want something more, there is a way to create your own aggregate. Only four functions need to be implemented, which can be done in SPL, Java or C. These functions are:
- init – initialises the data structure needed to calculate the aggregate and states the data types aggregate can be used on, called once at the beginning of aggregate execution
- iter – called once for each row in the dataset, adds the information brought by that row to current result value of the aggregate and passes it on to next iteration
- combine – called if aggregate is running in parallel, to combine current results of two threads together
- final – called at the end of aggregate calculation, returns the final result of the aggregate.
After that, one simple SQL statement creates an aggregate, for instance, if we want to create median aggregate, first we implement median_init, median_iter, median_combine and median_final functions and execute:
CREATE AGGREGATE median2 WITH
(INIT = median_init,
ITER = median_iter,
COMBINE = median_combine,
FINAL = median_final);
and it is ready to be used is SQL:
SELECT employee_id, median (salary) FROM income GROUP BY 1;
There is a nice post from Andrew Ford on how to create aggregates, take a look at it: User Defined Aggregates.
The limitation of the aggregate in general, from a data research point of view, is that it returns a single value, which describes the selected dataset in a particular way. If we want to find out something about the dataset, what does it mean to get only one number that sums it – be it a count, an average (mathematical mean), median or anything else? Experienced statistician might get a grasp on data distribution having these numbers if a data set is relatively small, but for a bigger data set, one should export the data and analyse it with some other tool. Or, for instance, pull it into R.
If an aggregate could return a picture, it would be possible to actually see the distribution of the data from within the SQL, before exploring it further and using some other tools.
So the idea is to return the blob from the final function, which contains the picture of a histogram, for example. For that to work, one should use an SQL tool which is capable of interpreting the blob data as a picture and displaying it (like ifmx-sql-editor, available here). Since all the data needs to be collected, init, iter and combine functions should be used to collect it all and process it in the final function. Currently, it is not possible to create the picture in SPL, so some kind of external library, whether in C or in Java should be used.
Here is an example on how to create a histogram aggregate using SPL functions and small Java class (all the code is available here!). In order to collect the data, a list data type is used. Each new row adds new value in the list and passes the list on to the next iteration. This is how the init, iter and combine functions look like:
CREATE FUNCTION histogram_init (dummy INT)
RETURNING LIST(INT NOT NULL);
RETURN LIST{};
END FUNCTION;
CREATE FUNCTION histogram_iter
(result LIST(INT NOT NULL), value INT)
RETURNING LIST(INT NOT NULL);
INSERT INTO TABLE (result) VALUES (value::INT)
RETURN result;
END FUNCTION;
CREATE FUNCTION histogram_combine
(partial1 LIST(INT NOT NULL),
partial2 LIST(INT NOT NULL))
RETURNING LIST(INT NOT NULL);
INSERT INTO TABLE (partial1)
SELECT * FROM TABLE(partial2);
RETURN partial1;
END FUNCTION;
The Java class resides on the database server and is called from the final function via the SYSTEM statement. Created image is put on the server and collected with the fileToBlob function and returned to the user.
Since one query can result in returning multiple images (if group by is used), the input data set name and the output image name both need to be pretty much unique and provided to the Java class which creates the image. To ensure uniqueness, a pseudo random number generator is used when creating file names. Here is the simplified version of the final function:
CREATE FUNCTION histogram_final (final LIST(INT NOT NULL))
RETURNING BLOB;
DEFINE...
LET rnd = sp_random();
LET in_file = "in_" || rnd || ".txt";
LET out_file = "out_" || rnd || ".png";
FOREACH
SELECT * INTO value FROM TABLE(final) ORDER BY 1
SYSTEM "echo " || value || " >> " || in_file;
END FOREACH
SYSTEM "sh Histogram " || in_file || out_file;
RETURN filetoBLOB("out_" || rnd || ".png", 'server');
END FUNCTION;
Java class should have a main method, accept two parameters, and create the given picture. It can use the simple Graphics object to create and store the picture. This is the idea:
public class Histogram {
public static void main(String[] args) {
// read the data from the text file args[0]
// calculate min, max, frequencies
// set up image
BufferedImage bImg = ...
Graphics g = bImg.createGraphics();
// draw histogram lines
// draw min and max
// write an image
ImageIO.write(bImg, "png", new File(args[1]));
}
}
Here is the example of the call and a screenshot of the SQL editor:
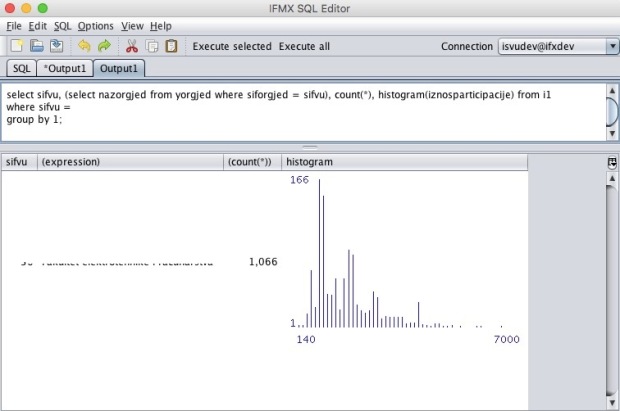
Simillary to this, other aggregates can be implemented as well. For instance box and whicker plot, violin plot, etc.
All the code mentioned here, as well as the median aggregate which is currently not implemented in informix, can be found at my GitHub (direct link: https://github.com/ognjenorel/ifmx-utils/tree/master/aggregates)
ETL for Graph Mining
Posted by ognjen in Hints, Scripts And How-Tos on October 24, 2017
In the world of data mining and analyses, there is a special set of mining methods and algorithms related to data in graphs. Graph is mathematical construct which contains vertices (nodes) and edges between them. Edge connects a pair of vertices and can be directed or undirected. As a data structure, graph is used in various extensions of this simple model. One of them is the “property graph model”, which allows vertices and edges to be uniquely identified, labeled (with one or more labels), and contain a set of key-value properties. There are a number of NoSQL graph databases which employ this data model.
Graph analyses provide measures and algorithms that help find some information which is otherwise very hard to find (i.e. using relational model or a data warehouse). Some examples: find most important people (in a social network of a kind), most important pages (on a web site or collection of sites), most important servers (in a network); decide who/what needs best protection (from flu, cyber-attacks, ..); find fake profiles and reviews on the web; cut costs (the traveling salesman problem) etc. Some of these measures are centrality measures (e.g. betweenness, closeness) or locality measures (e.g. indegree, outdegree). Also, there is a bunch of algorithms which are aimed towards identifying frequent patterns or subgraphs in a graph, or identifying interesting subgraphs or anomalies in a graph as well.
So, when I have a collection of data in my favorite relational database, how can I make use of all those graph algorithms? There are several possibilities, such as implementing the algorithms inside a relational database, but my answer to this is to perform an ETL (extract-transform-load) process in order to extract the data from the relational database and create a graph database from it. Then I can perform whatever analysis I want on this separate graph OLAP system. To do that, I defined a relational-to-graph ETL process which follows a set of 10 rules. These rules define the way the rows and their attributes (with regard to primary and foreign keys) are transformed to vertices, edges and their properties. I will not go into the details of these rules here, but if interested, please go to slides 30-40 of my IIUG2017 presentation (available here) to find explained rules with examples.
Is there any code? Of course there is :). I implemented the process as a series of stored procedures and a view, which need to be created in a relational database you want to extract the data from. After the calls:
execute procedure create_conversion_statements('~\my_working_dir');
execute procedure create_conversion_scripts('~\my_working_dir');
several scripts are created in the specified directory. One script is an SQL unload-transform script, which need to be executed in the same relational database to create a bunch of data files (one per table). Other files are Cypher scripts (Cypher is an open language used by several graph database systems, like Neo4j). These scripts can be executed in a graph database of your choice in order to create and populate it with the exported data. Once the data is in the database, you can start exploring it using Cypher or some of the graph algorithms.
All the code is open-sourced on GitHub, available here, under my ifmx-utils project.
The examples and more info can also be found in the IIUG presentation.
Formal description of the algorithm and the science around it is described in the paper Property Oriented Relational-To-Graph Database Conversion.
Hope you’ll find some of this useful.
Informix for Newbies
Posted by ognjen in Hints, Scripts And How-Tos on September 27, 2017
Mr Jan Musil, the man who does the best and the most complex Informix live demos most of us have ever seen, has put together a great document: Informix for Newbies (part one).
Document is in the form of slides, and it covers topics from download and install to simple configuration and instance monitoring. It is intended for people how have the basic Linux skills and understanding of how database (engine) works.
This kind of material is something that Informix community is always short off, so it’s more than welcome. Please feel free to download, use and share it: https://lnkd.in/dY387zC.
Thanks, Jan. We’re waiting for part two :).
Been a While
Posted by ognjen in Conference, General on September 26, 2017
Title of my blog is Informix on my mind, but since I haven’t published anything for some time, one could argue that Informix was not on my mind lately :). Correctly, but only to some extend. Most of the time I’ve been busy finishing my doctorate research which I procrastinated for too long and finally defending my PhD thesis. During this time, from my perspective, only couple of things worth mentioning happened (which doesn’t mean I’m going to stop writing).
First, I gave a presentation on IIUG 2017 Conference in Raleigh, NC. In this presentation I covered some of the advantages of graph analyses and gave arguments that graph structure could be used for OLAP purposes. I also presented the algorithm and my open-source implementation of an ETL process in order to create a graph OLAP database from Informix database. Stay tuned, I’ll cover this in more detail, along with links to the code and presentation in a separate post.
Second, and of much more importance to global Informix community, was the IBM-HCL partnership deal about Informix development and maintenance. It was announced before the IIUG Conference in April, and produced a lot of different reactions, from “IBM finally killed it” to “this is a long-expected good news”. I’m not going to elaborate on the details of the deal since there is plenty of information available (let me google it for you). I was among those who were optimistic about this change, since IBM’s work on Informix was slow, especially in the last couple of years. On top of that, many great people whom worked on Informix left IBM or were moved from the product.
Now, it has been nearly half a year since HCL partnership was introduced and we’re all still waiting for any sign that this works. In this time, HCL hired some very good and Informix-caring people, for which I have high hopes that will succeed in moving things in right direction. Yet, we are still to see what happens, and I wonder how much longer should we wait.
HCL, the community is here, listening and it’s anxious.
Serving Customized Documents from the Database
Posted by ognjen in Hints, Scripts And How-Tos on December 28, 2015
If your database serves an information system, there is a pretty good chance that system generates some written documents to end users – predefined reports or simply letters or some kind of official documents to be printed. In the case of relatively simple documents, i.e. not complicated multi-level detailed reports, application has to generate it using a template or some other meta-description of it, and fill it with a case-specific data. If there is a need to generate same documents from different apps (e.g. a web app and a desktop app), a solution to generate it and serve it right from the database might come in handy.
There are several ways to do this, but probably the simplest is to call the stored procedure (or a function) with the right parameters, which will return the document. Document templates which will be used should be stored somewhere in the database. The document generation function takes the appropriate template, searches for predefined tokens and replaces them with the correct data, depending on the input parameters. That’s why the template needs to be in some simple text format, perhaps RTF (rich text format) which allows neat formatting, could be prepared in most of the WYSIWYG text editors, can contain pictures and other advanced formatting stuff, and yet could be viewed as a plain text file, so tokens could be found and replaced easily.
Tokens should be predefined, agreed upon, and unique in a way that they could never be a part of a normal text. Some examples of tokens might be: REPLACEME_CURRENT_DATE, ##CUSTOMER_NAME## or %customer.id.number%. I suggest to define a single notation and stick to it. Just make sure the token format does not interfere with the special characters your chosen document format uses. After this, templates should be prepared in any rich text editor, like LibreOffice Writer or MS Word and stored in a database table with templates. Next, the document generating function has to be written. Depending on the size of the template, you might need to use some character data types like CLOB or LONGLVARCHAR (a new, still undocumented type), which make things more complicated. Main reason for this is the REPLACE function which doesn’t support bigger character types. Since we want to replace all tokens of the same kind in the document at once, we may store the file on the server, iterate through all the token types, replace them with proper values (using sed, for example), pull it back from the file system and return it to the user. Here is the outline of the function which might do that:
CREATE FUNCTION generateDocument ( document_id INT, additional parameters...) RETURNING CLOB;
-- define the variables
-- get the appropriate template from the table -- and store it on the file system using LOTOFILE function
-- fetch the values which will replace tokens in the template
FOR token IN (list of tokens)
-- replace each token in the file using SYSTEM 'sed...'
END FOR
-- pull the file from the file system using -- FILETOCLOB and return it
END FUNCTION;
This solution requires a smart blob space and file system privileges for the user executing it, but no other special demands exist. If you’re a fan of datablades, there is also a possibility of using a string manipulating blade functions which would make the replacements without meddling into a file system and leave the file system out.
Simple and meaningful row level auditing
Posted by ognjen in Scripts And How-Tos on November 29, 2015
Have you ever been asked about the history of a certain data? Like, who entered it and when? If you have, and you couldn’t figure out the answer, then you probably need some kind of auditing in place. There is a bunch of commercial (and free) products out there, most of them working with various data sources, not just Informix, some are only software solutions, other could be hardware-software combos. There’s one of IBM’s products out there aimed for this purpose, quite noticeable lately. If you know about it, then you’re probably already using it, or will use it at some point.
But what if you don’t need or can’t afford an expensive high tech solution to keep an eye on just a few tables? Or even an entire database. Well, luckily for us, Informix itself also offers audit feature, free of charge. On the second thought, maybe not.
Here’s the thing. Informix comes with auditing facility and it’s actually quite good. It covers various events it can keep track of (as much as 161 in version 12.10), some of which should be really enabled on every production system, if nothing else, for logging purposes. It also implements role separation, very important feature if you need to be confident that no one has tampered with your audit trail. It also enables you to create masks, or profiles, so you can audit different things for different types of users.
Unfortunately, most of the time, it can’t help you answer the question about the history of the data. When it comes to row level auditing, it’s mostly useless. There are four events which relate to row level auditing and could be turned on: INRW – insert row, UPRW – update row, DLRW – delete row and RDRW – read row. All things considering row level auditing on a live system should be used with utter caution, as these could produce enormous amounts of audit trails in a short time, especially the latter, as it will write one row in an audit trail file for each row read by the user. Just think of what would happen if a user would carelessly execute select statement without criteria.
At first, there was no way to select the tables which will be audited this way, so you either had to have INRW, UPRW and/or DLRW turned on for all tables or not. As this wasn’t very useful, it was enhanced soon enough. Now there’s a possibility to say which table gets to be audited this way, if some of these four events are turned on and the ADTROWS parameter is set to 1. This is done via the WITH AUDIT part of the CREATE TABLE statement:
CREATE TABLE example (a int, b int ...) WITH AUDIT;
If the table is already created, row level auditing for it could be added
ALTER TABLE example ADD AUDIT;
or removed
ALTER TABLE example DROP AUDIT;
at any time.
And now for the unfortunate part. The audit trail is written in the audit files. Every audit trail entry has the same structure, as explained here (LINK). While this format is useful or sufficient for some events, that is not the case with the row level events. For each of the row level events, only basic info is logged – tabid, partno and rowid. In the case of an update event, there are two rowids, an old and a new one. So basically, there is no way to figure out what was the value of a field before the update, or even which field changed. After the row was deleted, there is no way to find out what data it contained. The only way to know is to dig through the logical logs, as I previously explained, but that’s no way data history should be explored.
Bottom line, if you need to know your data history (inserts, updates and deletes), you should either acquire a tool which will help you with that, or you can try and set something up on your own. So here comes the happy ending. There are several way to do this, I’m showing the one with the triggers and shadow tables. The idea is to have a shadow table for each table you’re auditing, which has the same set of fields, and some extra fields, like username, operation performed on that row and a timestamp. Additionally, a set of triggers on the original table is needed, which will ensure the shadow table is filled. Informix can have multiple triggers on a single event since version 10.00 or so, so this is not a problem. If you’re thinking about implementation, there more good news – I’ve written and shared the code which will do that for you (a view and couple of procedures, find it here). All you need to do is to call the main procedure, provide the table name, dbspace name and the extent size of the shadow table, like this:
EXECUTE PROCEDURE createAuditForTable('exams, 'audit_dbs', 128);
It will create a shadow table in a designated dbspace, and name it like the original table, but with _ at the beginning. It will also create three triggers, with _ at the beginning of its name, followed by the table name and the operation name at the end, so it could be identified more easily (in this example, shadow table will be _exams and triggers will be named _examsinsert, _examsupdate, _examsdelete). These triggers will fire on each insert, update or delete operation on the original table and write actual row data, operation performed, user who performed it (USER variable) and the time of the operation (CURRENT variable) in the shadow table. Actual row is considered to be new row (in the for each row trigger) in the case of insert or update operation, and the old row in the case of a delete operation.
So from this moment on, you just have to query the shadow table in order to get the history of the original table. If the delete occurs, there is a whole row stored in the shadow table that can be seen. If the update occurred, you can find the previous row with the same primary key to compare the differences. Once you decide that no more audit is necessary on a table, simply drop the shadow table and these triggers.
Obviously, there is a storage space required for this, but so is for every other type of auditing, except this one is managed inside the database. It’s easy to govern and explore it, only SQL interface is needed.
There are security issues at place here, since no real role separation can be implemented. Triggers could be disabled or dropped, shadow tables with audit trail could be tampered with. Some problems could be solved by eliminating users with elevated permissions, like resource or DBA, and part of it could be solved by storing or moving the shadow tables to another server. But still, database system administrator (DBSA, i.e. informix user) can override all of this. So if you need to be in compliance with some kind of regulation, this type of auditing is not for you.
Otherwise, if you need to know your data history from an end-user point of view, this simple auditing can help you. All the code needed could be found here, it’s all open sourced via the GNU GPL v3 license. Feel free to use it and extend it. After noting that I cannot be held responsible if anything goes wrong :), just put it in your database, end execute the procedure with the correct arguments – tables you want audited.
Moving to GitHub
Posted by ognjen in Uncategorized on October 5, 2015
Google has announced a while ago it will be shutting down its Google Code service, so new home for some of the open-sourced tools should be found. That’s why I switched to GitHub and all the links in previous posts and software and tools page have been updated for their new location.
On top of that, I’m determined to continue sharing the code – my own and of some other developers, with their permission, of course. As I stated at the IIUG earlier this year, this is something we, the Informix community, should do to help Informix grow and become more accepted: share the knowledge, share the code – scripts, queries, tools we write and use. No matter how small or insignificant the code may be, there is always a novice out there who’ll find it useful.
With that regard, while migrating away from the Google Code, I was happy to see there were more than 2350 downloads of the ifmx-sql-editor binaries. Hopefully it is useful to somebody out there, as it is to me :-). Some new additions to it are on the way as well. Stay tuned.
IIUG Conference 2015
Posted by ognjen in Conference, General on April 21, 2015
The IIUG 2015 Conference in San Diego is getting very close. Next week, throughout the conference with over 80+ presentations, keynotes and other events, the IIUG will celebrate its 20th birthday! And following the “conference for users, by users” policy, I will present on some of the tools (mostly open-source) and techniques my team uses in a daily work with Informix. It will be a run-through different software, from scripts and SQL tools to application development and testing techniques we use in development, maintenance and support of big information systems. Though some of the stuff will certainly be familiar to a part of the audience, I hope everyone gets to hear and learn about something new.
Find the info about the conference and the schedule at www.iiug2015.org. For developers, it should be especially pleasing to see a number of developer-oriented topics – Java, Hibernate, web security, etc – just follow the D track.
See you at IIUG 2015!
Continuing Strong in 2015
Gartner guys reacted on a recent analyst report which stated that in 2015, the industry would begin retiring Sybase and Informix products. We’ve already seen so many such reports stating Informix is dead, or will be in the near future, that I’m used to ignoring all of them, but it’s nice to see Gartner investigate and state the opposite.
Here is the link to the article (first there is a part on Sybase, and Informix follows). What gives additional warmth to the heart, is the recognition of an IIUG as one of the important things when talking Informix. Kudos, Donald and Merv!
What Does It Mean for Us?
The big announcement in the world of Informix the other day was IBM signing the agreement with Chinese company General Data Technology or GBASE, which is, based on information on their website, a key software enterprise in the state planning. The base of the agreement (copy of the news is here) is that IBM shares the code of Informix, and GBASE will (in support of the China government’s national technology agenda) modify its security to conform to standards of Chinese government. That modified Informix will then be used in the future database projects.
So this is obviously big news for Informix, because it guarantees the expansion of the product to a fast growing market, but what does it exactly mean for us, non-IBMers involved in the Informix business?
Well, I’m looking at this in a good faith, so my personal thoughts are positive. This kind of agreement will result in bigger demand for Informix experts, both domestic and foreign. I have to admit that I have no idea about the state of affairs regarding Informix experts in China, but I presume it is definitely possible there will be a need for database designers, architects, and even bigger need for DBAs to maintain the big installations we all imagine when thinking of databases in China. So it’s quite possible some of us will find our careers continuing somewhere in east Asia or telecommuting for a local partner in China. Other than that, new DBAs should be properly trained, so that’s also another opportunity for all of us involved in teaching and training. This also means the growth of Informix community, and hopefully there will be more international community members springing out of these systems.
But most importantly, this means a long term survival of Informix as a product, which is of course in the best interest of all the Informix people. As Mr. Art Kagel said, this is the proof Informix is here to stay. And a little dream for the end, to share with you… would be nice to have this kind of commitment in other countries as well. Just saying.
RSS Links

